Last year we published our ML workflow landscape. One category we’ve seen continued interest in is data labeling, the process of attaching meaning to different types of digital data like audio files, text, images, and videos. Our research suggests themes in the data labeling segment include: 1) data is the new oil, 2) dark data is valuable, 3) deep learning algorithms are a driver, 4) hand labeling can be expensive, and 5) automation is important. The data labeling market is over $1.5B today and expected to grow at a double-digit CAGR over the next five years. We categorize +30 offerings that represent different approaches. We are excited about innovation in the space and look forward to speaking with startups offering data labeling solutions. Over the past few months we spoke to dozens of data scientists and ML engineers about data labeling. Our conversations unearthed five themes:
-
[Data is the new oil] . Data is a foundational component of training models. It is a day one concern. Andrew Ng stated data is the rocket fuel needed to power the ML rocket ship.
-
[Dark data is valuable but largely inaccessible] . Dark data like scientific articles, government reports, medical images, etc. are hard to use for training data because it isn’t machine readable. IBM estimates that only 20% of data is visible to computer systems, leaving 80% categorized as dark. IBM forecasts dark data will grow to +93% by 2020. Tagging dark data can improve model’s precision and expand use cases.
-
[Supervised learning needs more data than other model types] . In supervised learning, algorithms learn from labeled data. When the number of parameters and/or the problem’s complexity increases, the data volumes needed increase. The problem of having more dimensions yet small data volumes can result in overfitting. Training data is a bottleneck.
-
[Hand labeling data can be expensive] . Data scientists often spend up to 80% of their time cleaning and prepping data. It not only takes a lot of time but it can be financially expensive. Many large organizations bring data labeling in house (e.g. Google, Facebook, etc.). Our channel checks suggest managed services can be pricey at scale (100K+ images).
-
[Automated data labeling is key] . Solutions leveraging ML to automate labeling will be best-positioned to win because they won’t need to build a large workforce, train labelers, and deal with quality control to the same degree. Their solution will also offer a better margin structure for the customer and accelerated time to value.
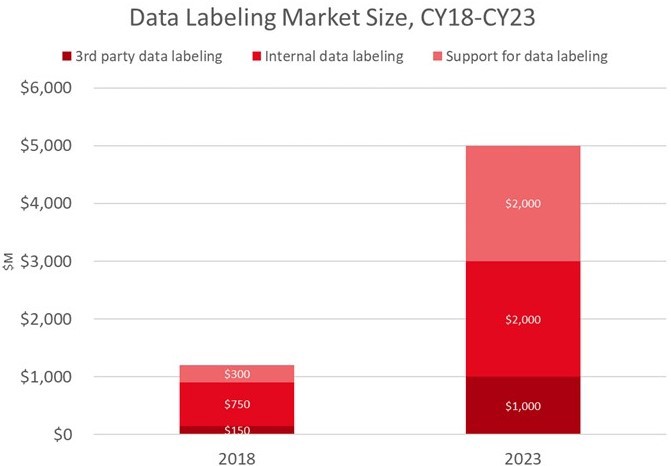
[The data labeling market] was $1.5B in CY18 and is expected to grow to $5B in CY23, a 33% CAGR. The market for third-party data labeling solutions is $150M in CY18 growing to over $1B by CY23. According to Cognilytica Research, for every 1x dollar spent on third-party data labeling, 5x dollars are spent on internal data labeling efforts, over $750M in CY18, growing to over $2B by end of CY23.
[The data labeling market]
There are numerous approaches to data labeling: 1) internal labeling programs, 2) managed services, 3) industry-specific managed services, 4) crowdsourcing, 5) data programming, and 6) synthetic labeling. We will publish a separate post discussing synthetic data shortly. Internal labeling assigns tasks to an in-house data science team or experts. This approach is popular at businesses performing ML at scale like Google. It can generate predictable results with high accuracy labels but can take a significant amount of time and resources. With this approach businesses leverage labeling software. Managed services offer APIs that allow businesses to upload their data that is labeled by humans, who often reside abroad. This approach can be more costs-effective at smaller scale but can struggle with quality control. Over time, these systems can collect enough data of a particular type that they can become intelligent and streamline data labeling using auto- classification. We also breakout managed services that are specific to an industry like healthcare or agriculture. Crowdsourcing, which we don’t exhibit below, pays individuals to generate data for predefined actions. For example, TwentyBN has a network of individuals that perform physical actions like a “thumbs down” and offers custom data collection. Data programming uses scripts to label data to avoid manual work. A generative model learns the accuracies of the labeling functions without any labeled data, and weighs their outputs accordingly. It can even learn the structure of their correlations automatically, avoiding double-counting problems. Then the platform generates probabilistic labels that can be used to train a ML model. This approach can be useful for cleaning up “noisy data” and empowering subject-matter experts to label data. We categorize over 30 offerings across
[four of the categories]
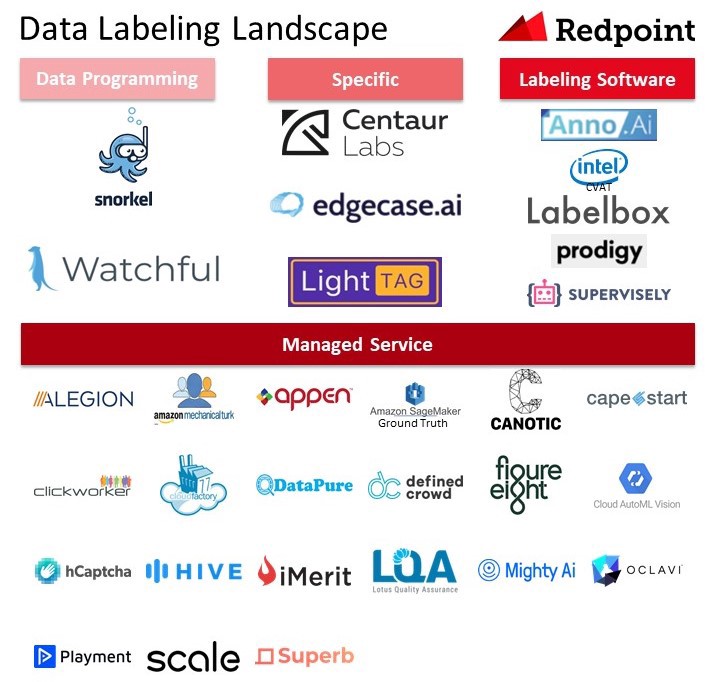
[four of the categories] . About half the solutions below have raised venture money over the past two years. Venture capitalists continue to invest in the category as exemplified by Labelbox’s recent $10M Series A from Gradient Ventures. In addition to capital raises, incumbents are starting to acquire startups like Appen’s purchase of Figure Eight for $300M in March 2019.
The appetite for labeled data to train ML models is only increasing. There are numerous trends that can catalyze startups to become enduring businesses and attack the multibillion dollar market. If you or someone you know is building a data labeling business, we would love to talk.